谷歌、亚马逊、奈飞数据科学家面试题解析!看看你在第几道题上卡住了?
原创:MarTechApe
这篇文章是专门为那些希望跟随自己的热情成为/转变为数据科学家的人而写的。数据科学是需要不断提高自身技能的领域,同时每天都要学习开发机器学习算法中的基本概念。因此,事不宜迟,让我们直接探讨一些可能对你下一次面试有用的问题和答案!
问题1:共线性如何影响你的模型?
答:共线性是指两个或多个预测变量(自变量)彼此有高相关度的情况。下图展示了两个共线性变量。变量1与变量2严格线性相关,其Pearson皮尔逊相关系数为1。因此,当两个变量同时放入机器学习模型时,其中一个将表现得像完全像噪音。
Pearson相关系数(Pearson CorrelationCoefficient)是用来衡量两个变量X和Y之间的相关程度(线性相关),其值介于-1与1之间。
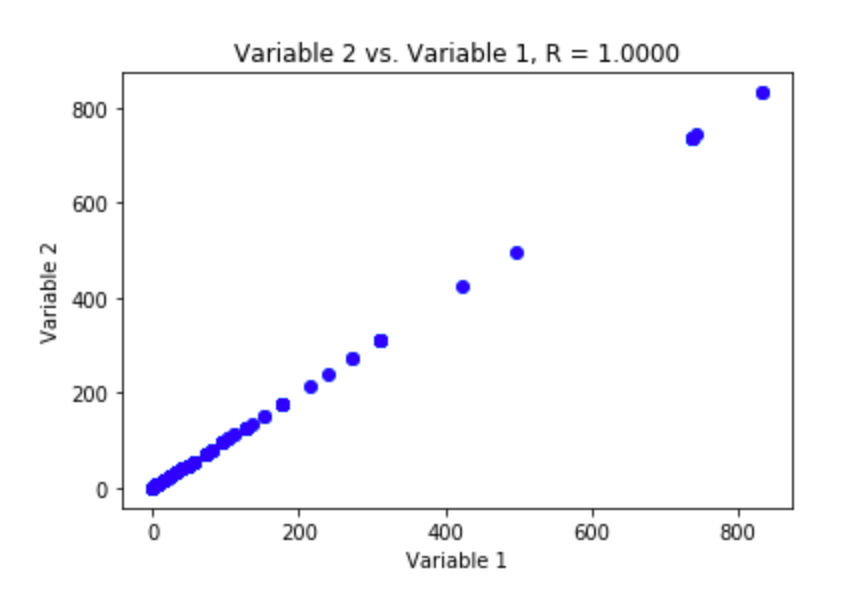
共线性的存在在回归类型的模型中会引发问题,因为很难区分出共线性变量对结果的影响。换句话说,共线性降低了回归系数估计的准确性,并导致误差的增加。这最终将导致 t 值的下降。在存在共线性的情况下,我们可能无法拒绝原假设。
检测共线性的一种简单方法是查看自变量的相关性系数矩阵。如果矩阵中存在一对高度相关的变量,那么该数据集则存在共线性问题。
不幸的是,并非所有的共线性问题都可以通过检查相关矩阵检测到:即使没有一对变量具有特别高的相关性,共线性也可能存在于三个或更多变量之间。这种情况称为多重共线性。
对于这种情况,我们会选择一种更好的评估多重共线性的方法,叫做计算方差扩大因子(Variance Inflation Factor,也称VIF:是表征自变量观察值之间多重共线性程度的数值)来代替检查相关性系数矩阵。每个变量的VIF可以使用以下公式计算得到:

其中R-square是这样得到的:将当前你要计算VIF的这个自变量X作为因变量,对所有其余的自变量做回归,所得到的回归模型的R-square,就是VIF公式里的R-square。如果VIF接近或大于10,一般认为存在共线性。
面对共线性问题,有两种可能的解决方案。一种是删除冗余变量。这可以在不影响回归拟合的情况下完成。第二种解决方案是将共线性变量组合产生一个新的自变量,来代替原来的共线性变量。
问题2:模型正则化是什么意思,线性模型将如何实现正则化?
答:正则化是用于约束机器学习模型的术语。减少机器学习模型中过度拟合现象的一种非常有效的方法就是减小自由度。自由度越小,模型越不容易过度拟合数据。例如,正则化多项式模型的一种简单方法是减少多项式自由度。但是,对于线性模型,正则化通常是通过约束模型的权重来实现的。因此,除了线性回归外,岭(Ridge)回归,套索(LASSO)回归和弹性网模型具有三种不同的方式来约束权重。为了更全面的论述,先从线性回归的定义开始:

y-hat是预测值(或,因变量)
n是特征数量(或,自变量个数)
x_i是第n个特征值(或,第n个自变量)
Theta是模型参数或称为特征权重(或,自变量系数)
线性回归模型的均方误差成本函数定义为:

其中ThetaT是theta的转置(行向量而不是列向量)
Ridge回归:是线性回归的正则化版本,即在成本函数中添加了一个附加的正则项。这迫使学习算法不仅要拟合数据,而且还要使模型权重尽可能小。请注意,仅在训练期间将正则化项添加到成本函数中。训练完模型后,可以使用线性回归模型性能指标评估模型的表现。

超参数Alpha控制要对模型进行正则化的比例。如果alpha为零,则Ridge回归仅是线性回归。
Lasso回归:Lasso回归是线性回归的另一种正则化版本:就像Ridge回归一样,它向成本函数添加了正则项,但使用权重向量的L1范数而不是L2范数的平方的1/2。

Lasso回归的一个重要特征是它趋于完全消除最不重要特征的权重(即将它们设置为零)。换句话说,Lasso回归会自动执行特征变量选择并输出稀疏化模型(即具有少量非零特征权重的模型)。
弹性网络回归:这是Ridge和Lasso回归之间的中间地带。正则项是Ridge和Lasso的正则项的简单组合,可以用参数“ r”控制。当r = 0时,弹性网络等效于Ridge回归,而当r = 1时,弹性网络等效于Lasso回归。

总之,回归模型最好至少要添加一点正则化,尽量避免直接使用纯线性回归。Ridge是一个很好的默认值,但是如果在特定数据集中只有少数自变量有用,则应使用Lasso回归模型。通常,Elastic Net优于Lasso,因为当变量数量大于实例数量或多个变量紧密相关时,Lasso回归可能会得到不合理的结果。
问题3:请解释什么是决策树的成本函数?
答:在我们回答这个问题之前,必须了解决策树模型是通用的机器学习算法,可以执行分类和回归两类任务。这两类任务的成本函数也是不同的。
1. 分类类型问题的成本函数:
在我们了解成本函数之前,我们先解释一个重要的概念:基尼不纯度(Gini impurity)基尼不纯度表示一个随机选中的样本在子集中被分错的可能性。
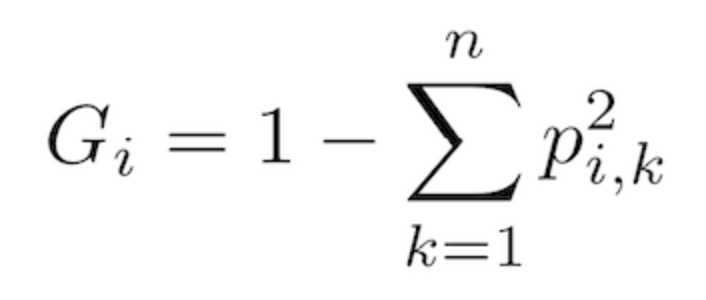
假设一个决策树将整个训练集分成n类,则“p”是在第i个节点时,第k类样本在训练集中占的比率。
这是什么意思呢?让我们以鸢尾花为例子,来了解一下!数据科学初学者拿来练手的一个最好的小项目就是分类鸢尾花,这项目很适合新手,因为非常简单易懂。鸢尾花有三个品种,分别是: Setosa、Versicolor、Virginica,他们的主要区别是花瓣宽度。

▲三种品种的鸢尾花
下图是一个简单的2层的鸢尾花分类决策树模型。这个算法最终把鸢尾花分成三个种类(Setosa、Versicolor、Virginica),分类的逻辑也非常简单。此处,鸢尾花数据集在根节点上根据“花瓣宽度”的这个特征变量先被分成两类。如果花瓣宽度小于或等于0.8,则算法进入第一层左侧,这些鸢尾花属于Setosa。如果不是,则转到第一层右侧,然后仍然是根据“花瓣宽度”进行进一步划分。此时,第一层的右节点还有100个的样本,其中0个属于Setosa,50个属于Versicolor,剩余50个属于Virginica。

因此,第一层右侧这个节点的基尼杂质为0.5:

类似的,第一层左节点的基尼杂质为0,因为所有训练实例都适用于同一类花名。该节点实质上是“纯”的。
好了,了解了什么是基尼杂质后,让我们回到最初的问题。基于分类和回归树(CART)算法的决策树模型该根据单个特征变量(k)和判断阈值(t)将一个数据集分为两个子集。在鸢尾花数据集中,单个特征k为“花瓣宽度”,第一层的判断阈值(t)为0.8。那么如何选择得到k和t?我们需要找到一对(k,t), 能将训练数据集分类成两个最纯子集。因此,算法试图最小化成本函数的公式如下:

其中G左或G右代表子集的基尼不纯度,而m代表子集的样本数。
2. 回归类型问题的成本函数:
对于回归树,成本函数非常直观。我们使用残差平方和(RSS)。下列公式显示了回归类型树的成本函数,其中“ y”是实际值,“ y-hat”是预测值。

问题4:如何向外行解释深度神经网络?
答:神经网络(NN, Neural Network)的思想最初源自能认识规律的人脑。NN通过机器识别,标记和分类原始数据来完成对数据对分析和解释。任何类型的现实世界数据,例如图像,文本,声音甚至时间序列数据,都必须转换为数字化的向量空间。
深层神经网络中的“深层”一词是指神经网络包含多层。这些层由进行计算的节点组成。节点可以类比为人脑中的神经元,当它受到足够的刺激时会触发。节点将来自原始输入的数据与其系数或权重进行组合,这些系数或权重将基于权重来抑制或放大该输入。输入和权重的乘积然后在下图中所示的汇合节点处总结,然后将其传递到激活函数,该激活函数确定该信号是否以及在何种程度上应继续通过网络传播以影响最终结果。节点层是一行这样的神经元状开关,当输入通过网络传送时,它们会打开或关闭。

深度神经网络与早期神经网络(例如感知器)有所不同,因为早期神经网络很浅并且仅由输入和输出层以及一个隐藏层组成。

问题5:可以用3分钟简述下你的数据科学挑战项目吗?
答:典型的数据科学面试过程始于实地数据分析项目测试。我做过两个,需要花费的时间可能会根据项目的复杂性而有所不同。第一次,我被要求在两天的内完成一个机器学习模型并撰写摘要总结。第二次则给我两个星期来解决问题。毫无疑问,第二次我需要处理对是一个更加困难的问题,因为数据集并不是很平衡。因此,三分钟的自我展示可以展示自己对当前问题的理解。要确保首先从解释你对问题的理解开始;再概述你解决问题的简要方法;以及在该方法中使用了哪种类型的机器学习模型和使用的原因,并突出模型的准确性。虽然这不是一道“技术题“,但这却是面试中的一个非常重要的问题,它使面试者能够证明自己是一个优秀对数据科学家,并且可以使用最新、最好的工具来解决复杂的问题。
如果你想为你的数据科学面试准备一份高含金量的数据科学项目、丰满你的个人作品集,那么千万不要错过MarTechApe携手美国第一大家具电商Wayfair的高级商业分析专家共同开设的《A/B测试企业级实战项目》!利用疫情期间,系统地掌握企业级别的A/B测试,使用百万量级的原始数据,搭建真实的A/B测试分析,掌握A/B测试在企业落地的完整流程,全方位提高数据科学技能与商业意识!

在《A/B测试企业级实战训练营》中,你将获得:
真枪实弹的A/B测试项目实操,真实数据+五大应用案例,从零学会A/B测试的里里外外!
为你建立一个完整的、专业的、深度还原大公司的的A/B测试项目,让你在面试时可以自信展示自己亲自做的案例,成功拿下offer!
从0到100真实操作A/B测试项目的全套流程:数据清洗、数据自动化处理、实验设计、实验执行、结果分析、报告展示。
经历真实工作场景中的、各大互联网科技公司里使用的A/B测试流程,以及适应不同商业场景的各类实验/准实验方法。学会工作中最重要的分析方法!
深度学习A/B测试实战中常见的测试陷阱及避免方法。
牢固掌握公司里A/B测试项目中的实际SQL应用,为A/B测试搭建数据库、清理数据、创建数据集。
学会用Python自动化实现A/B测试,为你的老板提高100%的工作效率!
接受系统的统计训练,打下坚实牢固的统计基础,彻底明白A/B测试的统计原理、分析方法、实验设计方法、抽样准则。
对互联网科技公司的深度剖析和指标介绍,让你自如面对各类面试考验!
各大互联网、科技公司A/B testing面试题解题步骤示范与详细解析。
点击下方图片跳转至课程介绍页,了解更多详情:

