Twitch数据科学家手把手教你拿下面试必考的SQL

数据科学方面的面试比较难找到准确的应对方法。它涉及多个学科领域的内容,意味着需要覆盖和练习众多方面才能准备妥当,不然面试的时候就会不知所措。
不管你是第一次面试数据科学的职位,还是即便已经有过一些经验了,这篇由Twitch(视频游戏实时流媒体视频平台,2014年被亚马逊收购)数据科学家亲撰的《拿下数据科学中的SQL面试》文章都值得一看。其中不仅包括了SQL基础知识介绍、常考内容示例,还有关于面试数据科学SQL测试的一些注意事项。
SQL基础知识
我参加过的每一场数据科学面试,都会以某种方式涉及到SQL。我几乎可以保证,在你找工作的过程中,一定会被要求写一些SQL语句给面试官,考察你的基本数据分析能力和数据处理逻辑。尽管一些数据科学家认为他们现在在处理大数据的时候要用Hadoop这样的分布式系统,但事实是,大部分现代数据存储仍然依赖(或允许)用SQL语法来检索和处理数据。
SQL的基本语句都很直截了当,但是在数据科学面试中遇到的SQL问题可能非常复杂。我猜读这篇文章的大多数人都有一些关于这门语言的经验,本文的其余部分假设你对以下内容已有所了解(若非如此,推荐你报名MarTechApe的《SQL基础班特训课程》,3小时掌握企业内最常用sql语句,可划到文末了解):
SELECT FROM JOIN WHERE (AND) GROUP BY ORDER BY LIMIT
现举个最基本的例子,一个SELECT…FROM语句将从指定的表中返回一组行和列,这些行和列的详细信息由放在关键字之后的内容决定。例如,要根据用户名的字母顺序来计算今天的网页浏览量,你可以这样写:
SELECT username, count(1) as number_of_views FROM pageviews WHERE day = '2017-09-08' GROUP BY username ORDER BY username;
明白了的话我们就可以继续往下看了。
子查询(Subqueries)和公共表表达式(Common Table Expressions)
现在你知道如何检索一组行和列,这可能会让你通过面试官的第一个问题。但是更高级的问题将涉及子查询或公共表表达式(CTEs)。让我们讨论一下这些是什么以及如何使用它们。
CTEs和子查询允许获取数据的子集并使用名称存储数据的子集,然后从中选择并执行更多操作。这两个方法的功能几乎相同。子查询是将一个查询块嵌套在另一个查询块的WHERE或HAVING字句的条件中查询块。比如想得到营收额高于或等于在同一地区所有商店平均营收额的店铺ID。这张店铺表的别名为“s“:
SELECT store_id, zipcode, revenue FROM stores as s WHERE revenue >= (SELECT Avg(revenue) FROM stores WHERE s.zipcode = stores.zipcode) ORDER BY zipcode;
上面是一个较为简单的例子,而更复杂的子查询可以层层嵌套。这里我主要关注CTEs,因为我认为它的语法更易于阅读。此外,CTEs会预存子查询的结果,所以运行速度通常比子查询要快。尤其是当某个子查询的表被重复使用的时候,效率会显著提升。
假设你被问到如何计算某个用户下达订单之间的平均时间。你有一个名为transactions的表,该表包含用户名和交易时间。要解决这个问题,你需要将每个交易时间与该用户的下一个交易时间放在一行中。一个查询并不能解决所有问题:你需要先提取一个用户的交易,将其存储在CTEs中,然后将它与此用户之后的交易连结,以便计算平均时间。这可以是这样的:
/*首先,找出2017年9月8日所有user_a的交易记录*/ with user_a_trans as ( SELECT username, time FROM transactions WHERE day = '2017-09-08' AND username = 'user_a'), /*将每一条交易与在它之后发生的所有交易合并在一张表格里*/ joined_trans as ( SELECT username, time, future_times FROM user_a_trans a INNER JOIN user_a_trans b ON b.time > a.time), /*使用MIN()函数找出最近的下一次交易*/ next_trans as ( SELECT username, time, MIN(future_times) as next_time FROM joined_trans GROUP BY username, time) /*将前一次交易与下一次交易的时间差取平均值*/ SELECT AVG(next_time - time) as avg_time_to_next_transactionfrom next_trans;
如果你不能很好的理解这个查询的所有细节,完全没关系——熟能生巧。重要的一点是,复杂的问题需要分解成多个部分,并通过一系列CTEs来解决。
筛选(Filter),聚合(Aggregate),合并(Join)
当你遇到像上面这样的难题时,先花一分钟问问自己理想的表应该是什么样的,才能用一个SELECT语句来解决这个问题。在上面的例子中,理想的表是有一条包含每个交易的记录,以及还包含下一个交易时间的一列。
一旦你知道了你的最终表格是什么样的,你就可以逆向思考,一步一步地决定如何使用一系列CTEs将你的原始表格转换成面试官要求的最终输出。
通常,你可以对你的CTEs字符串执行以下步骤:使用WHERE进行筛选,使用GROUP BY进行聚合,使用JOIN进行合并,重复上述步骤。
在合并之前先进行筛选和聚合数据,可以编写最高效的SQL。合并的过程需要花费一定时间,因此在将两个表联结在一起之前,尽可能删减掉不需要的行,只保留有需要的行。有时,会无法先进行聚合,但是你通常可以通过至少一两个WHERE子句来限制最后要合并的表的大小。
需要注意的是,如果在同一个CTE中有一个JOIN句和一个WHERE句,那么SQL首先处理JOIN。换句话说,以下是非常低效的,因为它将先合并两个表,之后才对“2017年1月9日”之后的时间进行筛选:
SELECT * FROM table_a a INNER JOIN table_b b ON a.username = b.username WHERE a.day >= '2017-09-01'
正确的表达方式是在合并表之前使用CTEs进行筛选,如下:
with a as ( SELECT * FROM table_a WHERE day >= '2017-09-01'), b as ( SELECT * FROM table_b WHERE day >= '2017-09-01') SELECT * FROM a INNER JOIN b ON a.username=b.username;
再强调一次,这里的效率提高是由于先筛选到尽可能少的行,之后执行两个表的合并。
窗口函数
使用上述筛选Filter、聚合Aggregate、合并Join的过程可以解决大多数问题,不过有时候也会遇到棘手的SQL问题,需要使用窗口函数(Window Functions)来解决。
类似GROUP BY语句,窗口函数会将数据分成几个模块,并分别对每个模块进行操作。但与GROUP BY语句不同的是,行不会被合并。 以下为示例。
假设你需要处理一个表格,该表格每行代表一个观测项,观测量包括营收情况及其所在的州,你需要计算每个观测项的营收占该州总收入的百分比。
此问题棘手之处就在于你需要将单个值(具体某一行的营收)与汇总值(属于某一州所有行的营收汇总)进行比较。本例中,单个值是指特定观测项的营收,汇总值指某个州所有观测项营收的总和。在这种情况下,解决类似问题的好方法就是使用窗口函数。代码如下:
with state_totals as ( SELECT state, revenue, SUM(revenue) OVER (PARTITION BY state) as state_revenue FROM state_line_items) SELECT state, revenue/state_revenue as percent_of_state_revenue FROM state_totals;
窗口函数包含OVER子句。本例中,通过按州划分(PARTITION BY),可得到与每个行观测项关联的各州的汇总值,后续通过简单的除法,上述营收占比问题也就迎刃而解。
窗口函数支持大多数聚合(Aggregate)函数,包括SUM、COUNT或AVG等,但也有一些特殊语句只能用作窗口函数。例如RANK、FIRST_VALUE和LAG。在准备面试时,也应重点准备以上六类函数。
Union及Case语句
此外,还有一些SQL语句需要重点准备。一是Union语句,相对而言较简单。Union语句可以看作是Join函数的垂直形式,也就是说,Join函数是将数据表或CTE水平组合在一起,而Union语句则是将两个表堆叠在一起,形成一个包含原始表中所有行数据的表。Union语句需满足的前提是被组合的两个表具有相同的列,否则将无法按逻辑进行组合。
例如在下面这种情况下,使用union会很有用——已知两张分别对应两类交易类型的数据表格,需要通过一个查询来确定每种交易类型的数量。代码如下:
with sales as ( SELECT 'sale' as type FROM sale_transactions WHERE day >= '2017-09-01'), buys as ( SELECT 'buy' as type FROM buy_transactions WHERE day >= '2017-09-01'), unioned as ( SELECT type FROM buys UNION ALL SELECT type FROM sales) SELECT type, count(1) as num_transactions FROM unioned GROUP BY type;
上述操作首先从两个表中分别选择一个常数字段“type”(在本例中为“ sale”或“ buy”),然后对其进行union合并,最终得到一个大表,从而可通过单个查询进行分组及计数。
总体而言,当需要将两个表组合为一个总表时,Union语句就是答案。
Case语句则是另一个相当简单的概念,与R和Excel等软件中的ifelse函数完全相同,通常应用于将一组预定义值映射到另一组预定义值的情况。
例如,你可能希望将星期几所在的列转换为另一个变量,代表该天是否为周末。
SELECT CASE WHEN day_of_week in ('Sat', 'Sun') then 'Weekend' else 'Weekday' end as day_type FROM table_a;
如上所述,可以将字符串所在列(如“星期几”)转换为二进制变量,然后对其求和以计算表中周末的天数。
SELECT SUM( CASE WHEN day_of_week in ('Sat', 'Sun') THEN 1 ELSE 0 END) as num_weekend_days FROM table_a;
Case语句的应用非常灵活,可以使用一系列WHEN语句表示映射条件,将对应值映射到目标值,再使用ELSE语句描述剩余的情况。
结语
现在你已经初步了解了成功通过数据科学面试的SQL部分所需的所有知识。当然,练习是关键。试着给自己设置一些问题,然后使用上面描述的工具来解决它们。更好的办法是,找一块白板,在上面练习,这样在面试的时候你会感觉更舒服。
我还想就面试本身给大家提几条建议。
把每个问题分解成尽可能小的部分。这是清晰思考SQL问题的最佳方式,将帮助你一步一步地思考要实现每个步骤所需要的SQL命令。
大声说出你的解题过程。就像在学校里一样,你会因为展示你的作品而得到赞扬。如果你只是独自埋头在白板上写东西,没有与面试官交流让他知道你在做什么,他们将很难评估你的技能,尤其是当你没有得到最终答案的时候。
寻求帮助。无论你是否相信,但大多数面试官都希望面试者能通过面试,也乐于提供一些帮助,只要你能清楚地表达出自己的问题所在。换句话说,可以问一些诸如将整数转换为浮点数的正确语法是什么之类的问题,但是要避免问一些含糊不清的问题,这些问题可能表明您不知道如何处理您试图解决的问题。
课程推荐
MarTechApe宝藏级数据分析实操项目《营销组合建模训练营》帮助众多学员敲开了全美知名企业数据分析和商业分析工作的理想大门。整个项目里会手把手带你经历全套的企业内营销数据分析流程,从数据源概况、数据处理与可视化,到统计建模、深度诊断。同时配备SQL面试辅导和简历指导。每位学员将有一套亲自打磨的Data成果作品和一套Model成果作品,以及一段完整的可以写在简历中为客户解决实际问题的经历。
从2018年起,我们已经举办了共10期《营销组合建模训练营》,往期的学生们拿到了全美顶级的面试机会以及全职工作OFFER,组成了训练营的荣誉之墙:

Marketing Mix Modeling Bootcamp往期学员拿到的面试机会以及全职工作OFFER包括Google、Facebook、Twitter、LinkedIn、Uber、Wayfair、Walmart、Accenture、Pepsi、Bloomberg、Square、Deloitte、Salesforce、AT&T、JP Morgan、Mediamath、GroupM等互联网科技公司、咨询公司、广告传媒公司、金融机构。
现在项目第11期已开始招生,如果你希望通过这样一个项目在此秋招季中加速斩获理想Offer,就快来报名我们的《营销组合建模训练营》Marketing Mix Modeling Bootcamp吧!
下面是项目具体介绍:
1.营销组合模型训练营是什么?
营销组合模型训练营(Marketing Mix Modeling Bootcamp)是MarTechApe的宝藏项目,由全球最大广告集团 WPP美国办公室的数据总监以及营销分析经理共同授课。在训练营中,你将学习在真实商业情境中如何用营销组合模型解决广告营销最核心的问题——科学合理地评估不同广告对品牌和销售的影响,以统计模型的结果来科学优化广告预算。

训练营的学员收获了:
真正意义上的“用数据和模型解决营销中最重要的问题”的经历。
熟练掌握SQL、R、Tableau等时下最流行的数据处理语言,并用这些技能解决实际问题。
大大提高Media/Advertising Industry的商业意识,熟悉不同媒介渠道的广告活动对不同商业指标的不同回报率(ROI)与有效性(Effectiveness),学会用“营销效果”的视角看待营销活动,理解各大公司市场营销部门、消费者洞察部门的痛点。
跳出学校作业的框架,上手真正商业情境中、实际工作中的实战案例。让校园与实际工作无缝衔接。将学到的Analytics思维方式泛化到其他应用场景,面对Case Study建立系统性解决思路。
提升项目演示Presentation技能,学会如何从原始数据中挖掘具有意义的故事。为客户解决实际问题,提高Business KPI。
完成项目后,辅导老师将帮助你利用这一个惊艳的项目背景打造最引人注目的简历;所有学员获得内推机会,优秀学员获得一对一面试辅导。
2.学员对训练营评价如何?
Marketing Mix Modeling Bootcamp开办至今,收获了大量好评,学员们都觉得Bootcamp的质量非常高,在节课后给我们发来了很多让我们非常感动的评论:






3.训练营老师是谁?
1. 全球最大广告传媒集团WPP | 数据总监
商业分析高级专家
拥有7年数据分析经历
各类SQL、Tableau疑难杂症的go-to person
2. 全球最大广告代理公司GroupM | 营销分析经理
营销效果分析专家。为十多个每年广告预算上亿美元的大客户提供营销效果评估、销售预测等解决方案
拥有6年Marketing Mix Modeling等高阶分析经验,具有丰富的训练新人和带领团队的经验
毕业于Columbia University统计学系
4.在Bootcamp中可以学到哪些内容?
整个bootcamp分为广告数据源概况、数据处理与可视化、统计建模、深度诊断,共计24小时课时,在两个月内完成。
周末Online Live授课,课后完成老师布置的作业,助教团队在班级群随时答疑,直播录像永久回放。
课程内容涵盖了数据分析岗位的完整工作流程(analytics cycle):
数据收集 Data Acquisition
数据处理和清洗 Data Processing
数据可视化与商业洞察 Data Visualization & Data Story-telling
统计建模 Modeling
模型优化 Optimization
销售预测 Simulation
深度诊断 Side Diagnostics
结果展示 Presentation
每位学员将有一套亲自做的Data成果作品和一套Model成果作品,以及一段完整的为客户解决实际问题的经历。
结课后,每位学员获得提升简历的Project Experience完美描述,所有学员获得内推机会!优秀学员获得额外一对一面试辅导。
报名的学员可在开课前一周获得详细的Syllabus。
课程大纲:

学员在前四周会聚焦在数据处理和商业洞察上。学员会面对大量的营销活动数据(如Display、Search、Social、Video、TV等广告数据),根据Media Data的数据源与结构来处理纷繁复杂的数据。并用可视化来呈现出数据洞察。你将学会如何搭建一个数据库、如何利用SQL去处理未经处理的、大型原始数据集,并利用Tableau对数据进行可视化分析。你还将完成对一份数据的商业分析。简而言之,我们将以Data Processing >> Data Visualization >> Insights Generation这样一套体系,系统加强你的数据分析能力以及商业意识。

在真实的世界里,模型用来回答各类不同的商业问题,帮助决策者作出最优的决策。在本次bootcamp的第四~第八周中,你将建立一个真正的Marketing Mix Model!掌握模型最核心的秘诀,调整各类模型参数、学会解读模型结果、优化营销预算、精准预测销售走势。在这个过程中,学会将商业问题翻译成模型问题,用不同的分析手段来回答不同的营销问题,真正做到数据驱动战略决策。

在向你的观众解释Marketing Mix Modeling的模型结果时,Side Diagnostics(深度 诊断)往往是一个让你的受众通过商业意义来理解模型结果的重要手段。模型的解释力以及与商业可行性的融合性是决定你的受众是否“买账”的关键因素。因此,Marketing Mix Modeling专门加入深度诊断部分,教你如何用统计的方法说服你的受众!
5.上完Bootcamp,有哪些成果可以展示?
从变量可视化分析、模型解读、营销渠道分析,到战略洞察、PPT演示,学员的精致作业就是他们最好的训练营成果,这一份拿的出手的高品质项目,无论是LinkedIn还是面试展示,都会是脱颖而出的最佳帮手!
学员作品
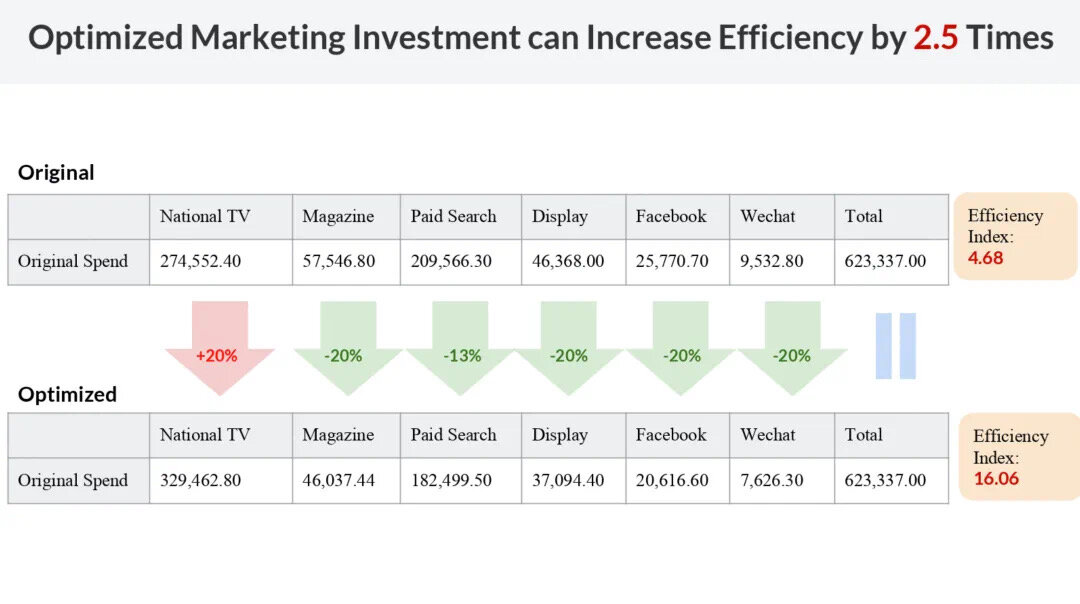
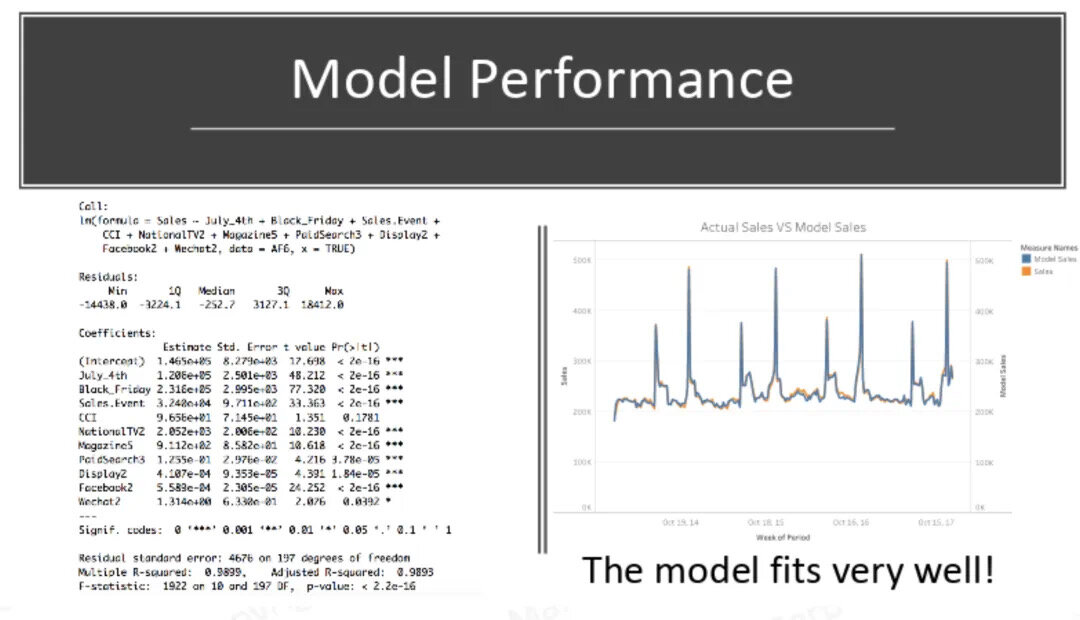
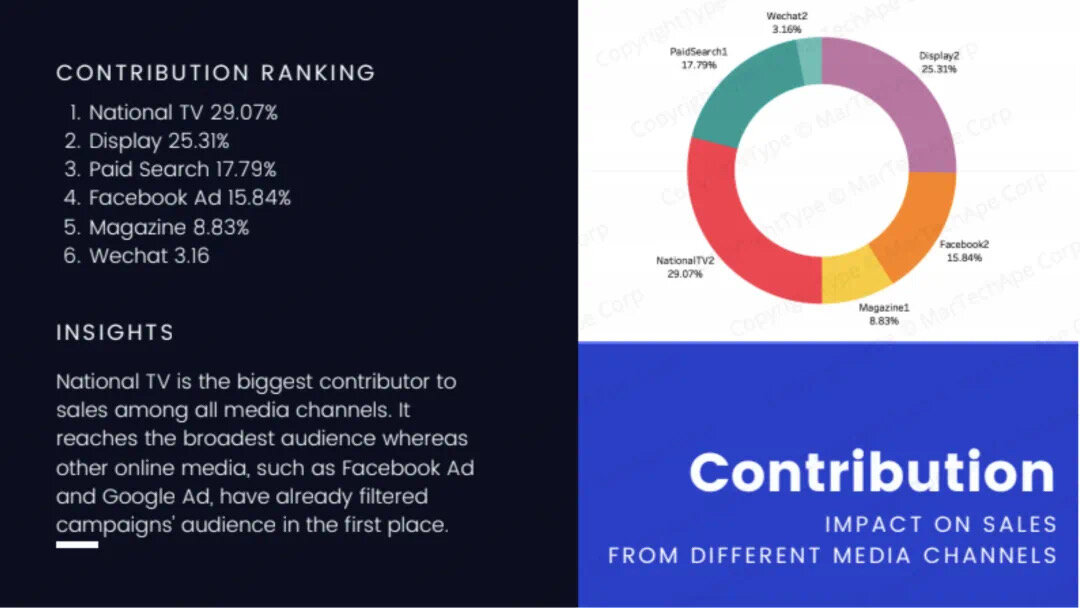

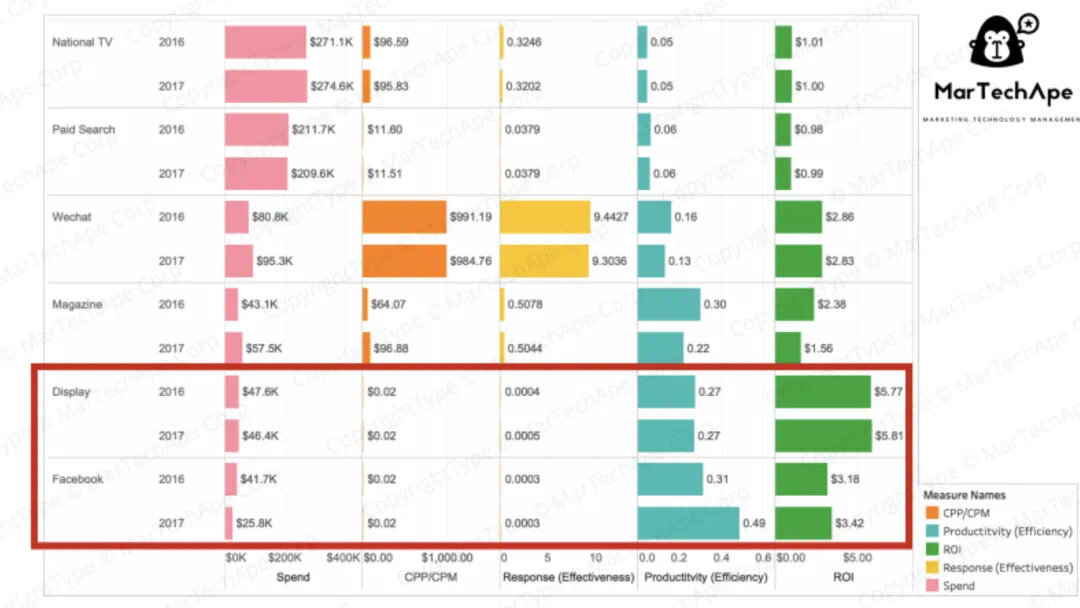
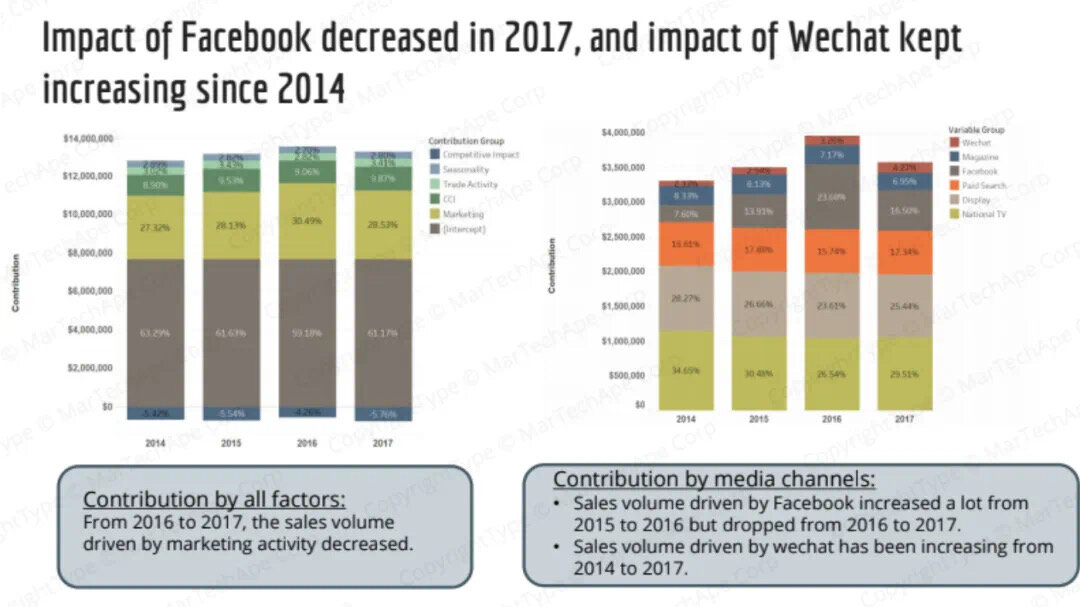
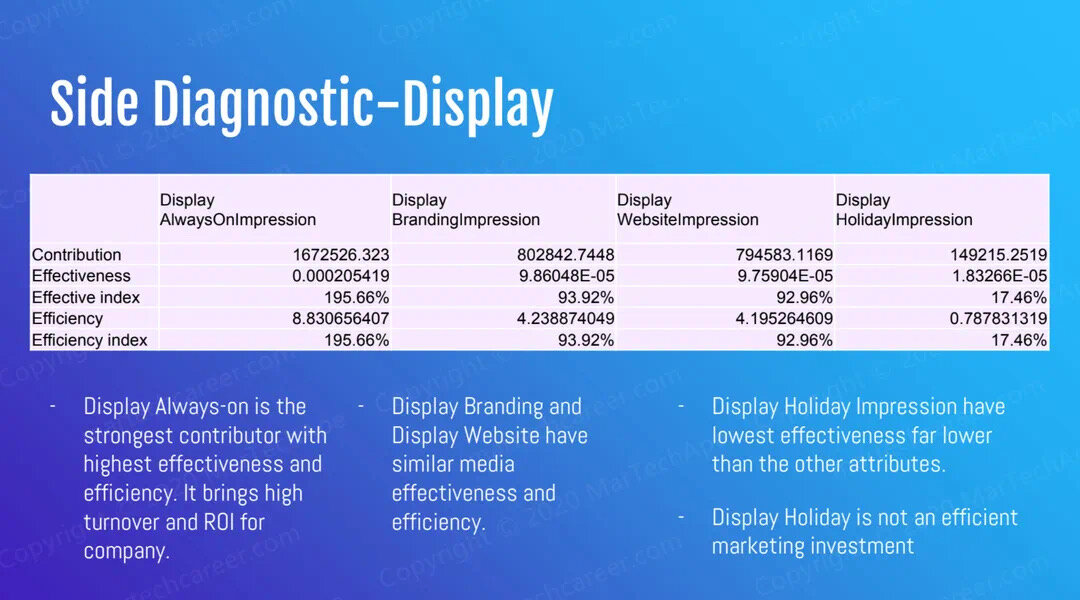
正是这些实打实的项目经验和能够直接拿到面试官面前展示的作品,让我们的学员在面试的时候信心倍增,让面试官刮目相看!
说了这么多,到底怎么报名这门干货十足物超所值的项目课程呢?
6.报名方式
长按二维码,添加小助手为好友,回复“MMM”,即可报名bootcamp:
小助手(微信ID:yvonne91_wsn)

价格规则
熟悉我们的老用户,应该知道我们一直都是实行阶梯价格的,这次也不例外:
先到先得、越早报名越优惠(原价$1999美元)。以下价格单位为美元:
第1名~第5名:1299美元
第6名~第10名:1499美元
第11名~第15名:1599美元
第16名~第18名:1799美元
第19名~第20名:1999美元(原价)
你现在的努力决定了两年后你在什么位置,如果红遍全网的谷歌“厂妹”有勇气破釜沉舟投资自己,你为什么不愿意付出成本提高自己的职场竞争力?两倍薪水并不是遥不可及的事情,而只是你当下的眼界和选择。
我们的课程,准备就绪,等你到来!
